Concepts
The core concepts of the Rules API.
Rules
Plugin logic is defined in rules: pure functions that map a set of statically-declared input types to a statically-declared output type.
Each rule is an async Python function annotated with the decorator @rule, which takes any number of parameters (including zero) and returns a value of one specific type. Rules must be annotated with type hints.
For example, this rule maps (int) -> str.
from pants.engine.rules import rule
@rule
async def int_to_str(i: int) -> str:
return str(i)
Although any Python type, including builtin types like int, can be a parameter or return type of a rule, in almost all cases rules will deal with values of custom Python classes.
Generally, rules correspond to a step in your build process. For example, when adding a new linter, you may have a rule that maps (Target, Shellcheck) -> LintResult:
@rule
async def run_shellcheck(target: Target, shellcheck: Shellcheck) -> LintResult:
# Your logic.
return LintResult(stdout="", stderr="", exit_code=0)
You do not call a rule like you would a normal function. In the above examples, you would not say int_to_str(26) or run_shellcheck(tgt, shellcheck). Instead, the Pants engine determines when rules are used and calls the rules for you.
Each rule should be pure; you should not use side effects like subprocess.run(), print(), or the requests library. Instead, the Rules API has its own alternatives that are understood by the Pants engine and which work properly with its caching and parallelism.
The rule graph
All the registered rules create a rule graph, with each type as a node and the edges being dependencies used to compute those types.
For example, the list goal uses this rule definition and results in the below graph:
@goal_rule
async def list_targets(
console: Console, addresses: Addresses, list_subsystem: ListSubsystem
) -> ListGoal:
...
return ListGoal(exit_code=0)
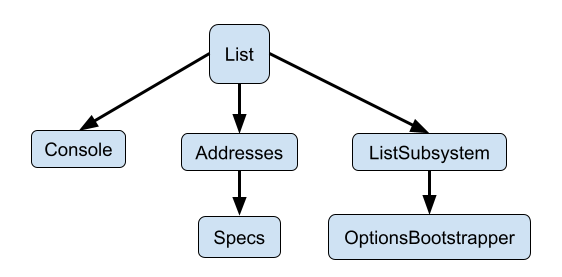
At the top of the graph will always be the goals that Pants runs, such as list and test. These goals are the entry-point into the graph. When a user runs pants list, the engine looks for a special type of rule, called a @goal_rule, that implements the respective goal. From there, the @goal_rule might request certain types like Console and Addresses, which will cause other helper @rules to be used. To view the graph for a goal, see: Visualize the rule graph.
The graph also has several "roots", such as Console, Specs, and OptionsBootstrapper in this example. Those roots are injected into the graph as the initial input, whereas all other types are derived from those roots.
The engine will find a path through the rules to satisfy the types that you are requesting. In this example, we do not need to explicitly specify Specs; we only specify Addresses in our rule's parameters, and the engine finds a path from Specs to Addresses for us. This is similar to Dependency Injection, but with a typed and validated graph.
If the engine cannot find a path, or if there is ambiguity due to multiple possible paths, the rule graph will fail to compile. This ensures that the rule graph is always unambiguous.
We know that rule graph errors can be intimidating and confusing to understand. We are planning to improve them. In the meantime, please do not hesitate to ask for help in the #plugins channel on Slack.
Also see Tips and debugging for some tips for how to approach these errors.
await Get - awaiting results in a rule body
In addition to requesting types in your rule's parameters, you can request types in the body of your rule.
Add await Get(OutputType, InputType, input), where the output type is what you are requesting and the input is what you're giving the engine for it to be able to compute the output. For example:
from pants.engine.rules import Get, rule
@rule
async def run_shellcheck(target: Target, shellcheck: Shellcheck) -> LintResult:
...
process_request = Process(
["/bin/echo", str(target.address)],
description=f"Echo {target.address}",
)
process_result = await Get(ProcessResult, Process, process_request)
return LintResult(stdout=process_result.stdout, stderr=process_result.stderr, exit_code=0)
Pants will run your rule like normal Python code until encountering the await, which will yield execution to the engine. The engine will look in the pre-compiled rule graph to determine how to go from Process -> ProcessResult. Once the engine gives back the resulting ProcessResult object, control will be returned back to your Python code.
In this example, we could not have requested the type ProcessResult as a parameter to our rule because we needed to dynamically create a Process object.
Thanks to await Get, we can write a recursive rule to compute a Fibonacci number:
@dataclass(frozen=True)
class Fibonacci:
val: int
@rule
async def compute_fibonacci(n: int) -> Fibonacci:
if n < 2:
return Fibonacci(n)
x = await Get(Fibonacci, int, n - 2)
y = await Get(Fibonacci, int, n - 1)
return Fibonacci(x.val + y.val)
Another rule could then "call" our Fibonacci rule by using its own Get:
@rule
async def call_fibonacci(...) -> Foo:
fib = await Get(Fibonnaci, int, 4)
...
Get constructor shorthandThe verbose constructor for a Get object takes three parameters: Get(OutputType, InputType, input), where OutputType and InputType are both types, and input is an instance of InputType.
Instead, you can use Get(OutputType, InputType(constructor arguments)). These two are equivalent:
Get(ProcessResult, Process, Process(["/bin/echo"]))Get(ProcessResult, Process(["/bin/echo"]))
However, the below is invalid because Pants's AST parser will not be able to see what the InputType is:
process = Process(["/bin/echo"])
Get(ProcessResult, process)
Currently, you can only give a single input. It is not possible to do something like Get(OutputType, InputType1(...), InputType2(...)).
Instead, it's common for rules to create a "Request" data class, such as PexRequest or SourceFilesRequest. This request centralizes all the data it needs to operate into one data structure, which allows for call sites to say await Get(SourceFiles, SourceFilesRequest, my_request), for example.
See https://github.com/pantsbuild/pants/issues/7490 for the tracking issue.
MultiGet for concurrency
Every time your rule has the await keyword, the engine will pause execution until the result is returned. This means that if you have two await Gets, the engine will evaluate them sequentially, rather than concurrently.
You can use await MultiGet to instead get multiple results in parallel.
from pants.engine.rules import Get, MultiGet, rule
@rule
async def call_fibonacci(...) -> Foo:
results = await MultiGet(Get(Fibonnaci, int, n) for n in range(100))
...
The result of MultiGet is a tuple with each individual result, in the same order as the requests.
You should rarely use a for loop with await Get - use await MultiGet instead, as shown above.
MultiGet can either take a single iterable of Get objects or take multiple individual arguments of Get objects. Thanks to this, we can rewrite our Fibonacci rule to parallelize the two recursive calls:
from pants.engine.rules import Get, MultiGet, rule
@rule
async def compute_fibonacci(n: int) -> Fibonacci:
if n < 2:
return Fibonacci(n)
x, y = await MultiGet(
Get(Fibonacci, int, n - 2),
Get(Fibonacci, int, n - 1),
)
return Fibonacci(x.val + y.val)
Valid types
Types used as inputs to Gets or Querys must be hashable, and therefore should be immutable. Specifically, the type must have implemented __hash__() and __eq__(). While the engine will not validate that your type is immutable, you should be careful to ensure this so that the cache works properly.
Because you should use immutable types, use these collection types:
tupleinstead oflist.pants.util.frozendict.FrozenDictinstead of the built-indict.pants.util.ordered_set.FrozenOrderedSetinstead of the built-inset. This will also preserve the insertion order, which is important for determinism.
Unlike Python in general, the engine uses exact type matches, rather than considering inheritance; even if Truck subclasses Vehicle, the engine will view these types as completely separate when deciding which rules to use.
You cannot use generic Python type hints in a rule's parameters or in a Get(). For example, a rule cannot return Optional[Foo], or take as a parameter Tuple[Foo, ...]. To express generic type hints, you should instead create a class that stores that value.
To disambiguate between different uses of the same type, you will usually want to "newtype" the types that you use. Rather than using the builtin str or int, for example, you should define a new, declarative class like Name or Age.
Dataclasses
Python 3's dataclasses work well with the engine because:
- If
frozen=Trueis set, they are immutable and hashable. - Dataclasses use type hints.
- Dataclasses are declarative and ergonomic.
You do not need to use dataclasses. You can use alternatives like attrs or normal Python classes. However, dataclasses are a nice default.
You should set @dataclass(frozen=True) for Python to autogenerate __hash__() and to ensure that the type is immutable.
from __future__ import annotations
from dataclasses import dataclass
@dataclass(frozen=True)
class Name:
first: str
last: str | None
@rule
async def demo(name: Name) -> Foo:
...
NamedTupleNamedTuple behaves similarly to dataclasses, but it should not be used because the __eq__() implementation uses structural equality, rather than the nominal equality used by the engine.
__init__()Sometimes, you may want to have a custom __init__() constructor. For example, you may want your dataclass to store a tuple[str, ...], but for your constructor to take the more flexible Iterable[str] which you then convert to an immutable tuple sequence.
The Python docs suggest using object.__setattr__ to set attributes in your __init__ for frozen dataclasses.
from __future__ import annotations
from dataclasses import dataclass
from typing import Iterable
@dataclass(frozen=True)
class Example:
args: tuple[str, ...]
def __init__(self, args: Iterable[str]) -> None:
object.__setattr__(self, "args", tuple(args))
Collection: a newtype for tuple
If you want a rule to use a homogenous sequence, you can use pants.engine.collection.Collection to "newtype" a tuple. This will behave the same as a tuple, but will have a distinct type.
from pants.engine.collection import Collection
@dataclass(frozen=True)
class LintResult:
stdout: str
stderr: str
exit_code: int
class LintResults(Collection[LintResult]):
pass
@rule
async def demo(results: LintResults) -> Foo:
for result in results:
print(result.stdout)
...
DeduplicatedCollection: a newtype for FrozenOrderedSet
If you want a rule to use a homogenous set, you can use pants.engine.collection.DeduplicatedCollection to "newtype" a FrozenOrderedSet. This will behave the same as a FrozenOrderedSet, but will have a distinct type.
from pants.engine.collection import DeduplicatedCollection
class RequirementStrings(DeduplicatedCollection[str]):
sort_input = True
@rule
async def demo(requirements: RequirementStrings) -> Foo:
for requirement in requirements:
print(requirement)
...
You can optionally set the class property sort_input, which will often result in more cache hits with the Pantsd daemon.
Registering rules in register.py
To register a new rule, use the rules() hook in your register.py file. This function expects a list of functions annotated with @rule.
def rules():
return [rule1, rule2]
Conventionally, each file will have a function called rules() and then register.py will re-export them. This is meant to make imports more organized. Within each file, you can use collect_rules() to automatically find the rules in the file.
- pants-plugins/fortran/register.py
- pants-plugins/fortran/fmt.py
- pants-plugins/fortran/test.py
from fortran import fmt, test
def rules():
return [*fmt.rules(), *test.rules()]
from pants.engine.rules import collect_rules, rule
@rule
async def setup_formatter(...) -> Formatter:
...
@rule
async def fmt_fortran(...) -> FormatResult:
...
def rules():
return collect_rules()
from pants.engine.rules import collect_rules, rule
@rule
async def run_fotran_test(...) -> TestResult:
...
def rules():
return collect_rules()